Abstract
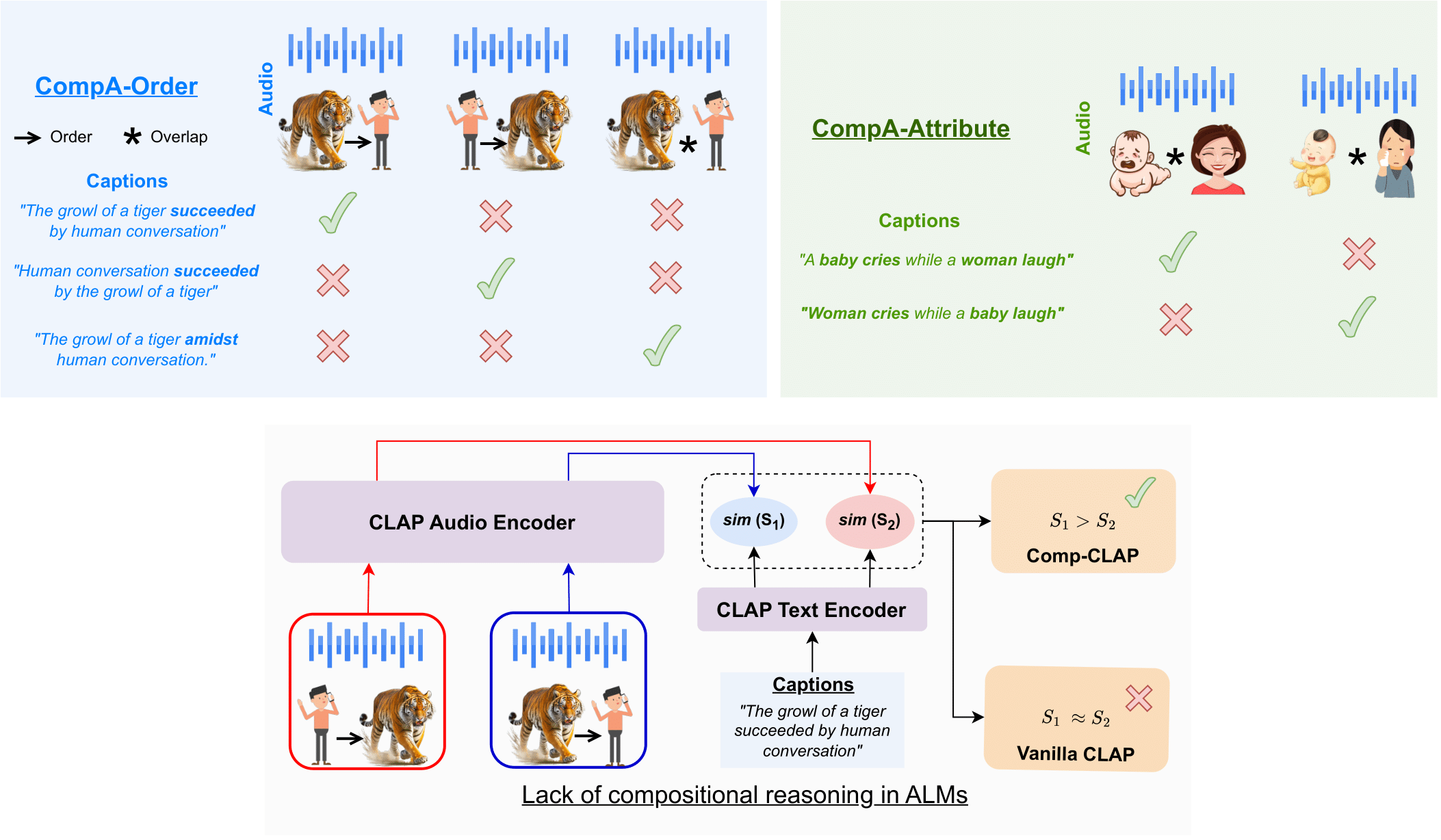
A fundamental characteristic of audio is its compositional nature. Audio-language models (ALMs) trained using a contrastive approach (e.g., CLAP) that learns a shared representation between audio and language modalities have improved performance in many downstream applications, including zero-shot audio classification, audio retrieval, etc. However, the ability of these models to effectively perform compositional reasoning remains largely unexplored and necessitates additional research. In this paper, we propose CompA, a collection of two expert-annotated benchmarks with a majority of real-world audio samples, to evaluate compositional reasoning in ALMs. Our proposed CompA-order evaluates how well an ALM understands the order or occurrence of acoustic events in audio, and CompA-attribute evaluates attribute-binding of acoustic events. An instance from either benchmark consists of two audio-caption pairs, where both audios have the same acoustic events but with different compositions. An ALM is evaluated on how well it matches the right audio to the right caption. Using this benchmark, we first show that current ALMs perform only marginally better than random chance, thereby struggling with compositional reasoning. Next, we propose CompA-CLAP, where we fine-tune CLAP using a novel learning method to improve its compositional reasoning abilities. To train CompA-CLAP, we first propose improvements to contrastive training with composition-aware hard negatives, allowing for more focused training. Next, we propose a novel modular contrastive loss that helps the model learn fine-grained compositional understanding and overcomes the acute scarcity of openly available compositional audios. CompA-CLAP significantly improves over all our baseline models on the CompA benchmark, indicating its superior compositional reasoning capabilities.
Key Contributions
- We develop two expert-annotated benchmarks, CompA-order and CompA-attribute, with majority real-world audios, that serve as a test-bed to evaluate the compositional reasoning of ALMs. CompA-order and CompA-attribute have 400 and 200 test instances respectively, where each instance has two or three audio-caption pairs. Each audio is different in composition, and each caption contains the same words but in a different order to account for the different compositions. The task of an ALM is to correctly match the audios with their captions. While CompA-order is used to evaluate the models’ ability to understand the order of occurrence between two acoustic events in an audio, CompA-attribute is used to evaluate the models’ ability to link attributes to specific acoustic events (attributebinding). More than 90% of audio snippets in CompA are sourced from real-world audio samples from AudioSet (Gemmeke et al., 2017) by expert annotators experienced in audio and language research. We discuss in Section 2 why current benchmarks do not evaluate compositional reasoning and how CompA serves as an essential step to fill this gap.

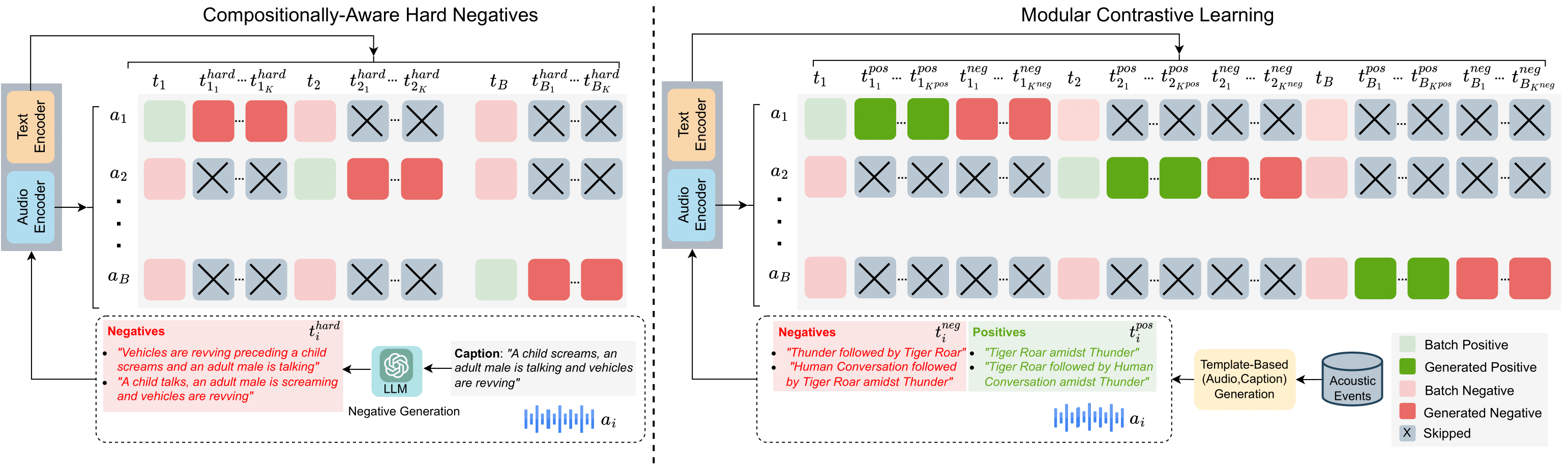
- We propose a robust learning solution for improving compositional reasoning in audio-language models. First, we propose several improvements to contrastive learning with composition-aware hard negatives (Yuksekgonul et al., 2023). Employing hard negatives for each audio in the batch has proven to be an effective solution and we propose the following improvements: (1) We formulate the objective such that the hard negative captions for a particular audio are ignored by other audios in the batch. (2) We use an LLM to generate semantically viable negatives. Additionally, due to the lack of compositional audios in current training datasets, we propose a novel dataset with 110k+ audio-caption pairs based on the AudioSet strong subset (Hershey et al., 2021). Next, we propose a modular contrastive learning objective that does not require any existing compositional audiocaption pairs. Our proposed solution leverages a template-based audio-caption creation approach and improves CLAP’s fine-grained attribute-binding and order-understanding capabilities. More specifically, we aim at aligning captions of various granularities to an audio, each of which represents a decomposed version of the audio scene. Additionally, we mine multiple negatives from the positives by interchanging orders and attributes. CompACLAP outperforms all our baselines on the CompA benchmark by 10%-28% while retaining performance on existing retrieval and zero-shot classification benchmarks.
Citation
@inproceedings{
ghosh2024compa,
title={CompA: Addressing the Gap in Compositional Reasoning in Audio-Language Models},
author={Sreyan Ghosh and Ashish Seth and Sonal Kumar and Utkarsh Tyagi and Chandra Kiran Reddy Evuru and Ramaneswaran S and S Sakshi and Oriol Nieto and Ramani Duraiswami and Dinesh Manocha},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=86NGO8qeWs}
}